Video Captioning
Automatic description generation from digital video

GitHub repository: https://github.com/bozliu/video-captioning
Abstract
Recently, interactive media material consisting of the medium text, audio, picture and video intrinsically has a multimedia style. With the assistance of advanced deep learning (DL) methods, some of the exceptional computer vision (CV) issues have been successfully resolved. Video Captioning is automatic description generation from digital video. In this article, a novel deep learning neural network architecture is introduced and implemented on the MST-VTT dataset by using I3D and 2DCNN to extract the features and fuse them with spatial, temporal and channel attention mechanism. In the perspective of model typology, the encoder-decoder structure is improved by adding a new block, reconstructor to reconstruct features and therefore to generate caption with better quality.
1 Standard Video Captioning System
Video captioning is a text description of video content generation. Compared with image captioning, the scene changes greatly and contains more information than a static image. Therefore, for the generation of text description, video caption needs to extract more features, which is more difficult than image caption. The recent mainstream methods of video captioning task are composed of two parts, video feature extraction part and video description generation part. The standard video captioning system architecture is shown in Figure 1.

2 Previous Problems
In the previous chapters, the basic framework of the video description model is introduced. The general video description model has a basic “encoding decoding” architecture. The encoding module is mainly used for video feature extraction, and the decoding module is mainly used for sentence generation. The training of the video description model usually uses backpropagation to maximize the probability of the next word given the ground-truth value at the current time. To be specific, cross-entropy and maximum likelihood estimation (MLE) is used to train the model and generate sentences. However, this training method brings some problems to the video description model
The first problem is that sentence integrity is not considered in the training. In the process of sentence generation, their quality should be evaluated from the perspective of integrity. However, the training method of maximum likelihood estimation does not consider the integrity of the sentence. It evaluates the correctness of a single word in the sentence. This training method will, to some extent, make the model biased.
The second problem is the singleness and unnaturalness of the generated statements. After training with the MLE method, the model will produce the most frequent words in the training set as far as possible in the process of generating sentences. This will lead to most of the sentences generated from the training set, and lack of diversity and naturalness. Therefore, the video generation model using MLE will have problems in the process of training and generating sentences, and these problems will eventually make our sentences lack diversity and naturalness compared with human sentences.
The third problem is that the simple “encoding decoding” structure cannot measure the relevance between the generated sentences and the visual features. If the generated sentences and the input visual features can be added with cross-domain similarity constraints, the relationship between the visual features and the sentence features can be enhanced, and the quality of the generated caption can be improved as well.
3 Proposed Deep Neural Network Structure
For a video captioning model, the generated statements should have the following characteristics. The first is authenticity. The generated statements should truly reflect the content of the video. The second is naturalness. The generated sentences should be close to the sentences expressed by human beings in the face of the same situation and conform to the grammatical rules. The third is diversity. The generated statements should be as diverse as possible, and different statements can be used to describe the same video content. In order to make our video captioning model have the above three characteristics, a reconstruction video description network is proposed based on multimodal feature fusion. The network structure is shown in Figure 2.

To start with, multimodal features are extracted from the input video information by feature extractor, and then the fused features are obtained by the feature fusion. The video features are input into the encoder to get the hidden state coding, and the captions are decoded by the encoder. Finally, the captions are encoded as reconstruction vectors, and the constraint reconstruction vectors are similar to the fused video features as much as possible.
The network is divided into two parts. One part is a sufficiently rich feature extraction module, and the second is the generation and reconstruction module of the caption. In the section of the feature extraction module, rich video features are the premise of generating high-quality captions. All available features are supposed to be used as far as possible. In the section of the capture generation and reconstruction module, most of the current video capture methods only use feedforward information and encoder -structure. CNN or other methods is used as an image encoder to process video or image to get visual features and LSTM / GRU is used as a decoder to generate tokens circularly. However, the feedback information from the text in the target domain to the video in the source domain has never been used, and this feedback information is also significant to improve the model. The reconstruction process provides a constraint for the decoder: embedding more information from the source domain into the target domain. Since the source domain can be restored, there must be much similar information. In addition, it is difficult to approach the original visual image directly. It can only approach the original visual features.
4 Features Extraction
Video content is more abundant than image. Video feature extraction is a typical field that can use multimodal feature extraction. Video features can be simply divided into visual features, motion features, auxiliary tag information, audio features, Theoretically, it includes 2D-CNN features, 3D-CNN features, and semantic features.
4.1 2D-CNN Features
The performance of the state-of-the-art convolutional neural network (CNN) in image recognition has surpassed that of human beings. Using CNN pre-trained on ImageNet [1] on large image data set, the common features of the input image can be effectively extracted. The current mainstream CNN networks are VGG [2], GooglNet [3], ResNet [4], Inception network [5], EfficientNet [6]. When extracting 2D-CNN features of video, a specified number of video frames are sampled from the video. The sampling method can be random sampling or equal interval sampling. The obtained video frames are sent to the pre-trained CNN, and the higher activation vectors of CNN are retained as video feature embeddings
4.2 3D-CNN Features
Although 2D-CNN can extract video frame information, it also destroys the temporal information between video frames to a certain extent. In order to extract video frame information and better retain the context information in the video, Ji s et al. proposed to use 3D-CNN [7] to extract video features. 3D-CNN can perform convolution operation both on the spatial and temporal dimension of the video. Therefore, the temporal characteristics of the video are well preserved. Some popular 3D-CNN methods are TSN [8], C3d [9], I3D [10], S3D [11].
4.3 Semantic Features
Semantic features refer to a large class of features that can capture the semantic content in the video. It can be categized into spatial semantic information (i.e. object information) and temporal action information. By adding this two semantic information, the quality of video features can be effectively improved.
Spatial semantic information can be extracted by using pre-trained target detectors. For example, fast R-CNN [12] proposed by Ren s et al. In 2017, and CenterNet [13] proposed by Zhou x et al. In 2019, when using spatial semantic information, the activation vectors at higher levels in these target detector networks can be used as features, it can also enhance the richness of features by using the video level category information obtained by the detector [14].
Action information in temporal sequence can be extracted by a pre-trained action recognition network, such as the TPN network [15] proposed by Yang C et al. and the action recognition method proposed by Zhu y et al. In addition, the temporal action information does not have to be obtained by CNN. For example, Aafaq et. al [16] proposed a method using hierarchical Fast Fourier Transform to extract the temporal information of the video.
4.4 Motion Features
Motion feature is essential for motion information and temporal interaction in video. It contains multiple frames of video information and can effectively supplement the static visual appearance. Optical flow is a typical motion feature. 3D CNN methods C3d [9], I3D [10], S3D [11] can selectively output motion features while learning visual features. In order to obtain motion features through these networks, it is necessary to use the optical flow information between the input frames of the network as the motion features of the video, and the high-level activation vector output by the network as the optical flow information.
4.5 Audio Features
To some extent, audio information can overcome the limitations of visual features, and distinguish those confusing scenes caused by visual information. For example, audio information can distinguish between people who are speaking and people who are not speaking. Mel-frequency cepstrum (MFCC)is a widely used audio feature information [19]. MFCC uses the Mel frequency cepstrum coefficient to process audio information. In recent years, with the rapid development of CNN, there are also work to learn audio features by using CNN, such as the VGGish-BiGRU network proposed by Shi l et. al [20]. However, since not all video data sets will contain audio information, it is not necessary to improve network performance by using audio features.
5 Feature Fusion
Feature fusion refers to fuse the extracted multi-modal features to achieve fixed-length features to be sent to the network, and feature fusion is also conducive to reducing the calculation cost. Feature fusion based on attention mechanism [21] is a common feature fusion method.
5.1 Temporal Attention Mechanism
In the video, each frame represents the information of different time. The visual features of each frame are a relatively complete semantic information expression. It expresses the global temporal information in the video, such as the sequence of objects, actions, scenes and people in the video. This kind of information may continue in the whole video sequence, A good video captioning model should be able to pay attention to the important temporal information in the video sequence. Through the attention in the time domain, the importance of different frames can be grasped.
For a given video, the video feature set F={f₁,f₂,…,f_n} can be extracted by 2D-CNN. The Set F corresponds to the features of the whole video. The temporal attention mechanism [43] can be applied to weigh the features at different times to obtain the global feature of the video at different times, as follows:

5.2 Spatial Attention Mechanism
Video contains both global temporal features and local temporal features. These features are usually the expression of fine-grained features of video for some actions, or fine-grained features for identifying important areas of the image, such as the area where people are in the image. Generally, these features only appear in some regions of a video sequence. If the video frame is pooled globally, the ability to capture the local information will be weakened. In order to make the model have the ability to capture local video information, a spatial attention mechanism can be applied.
5.3 Channel Attention Mechanism
CNN network will produce a different number of feature maps in each layer, namely channel features. Zeiler [22] experiments show that the feature maps of different layers of the CNN network can show different semantic information. Specifically, the low-level feature map shows low-level visual features such as texture and colour, while the high-level feature map shows high-level semantic features such as some objects with different spatial features. These different feature maps are caused by the fact that the CNN network contains many convolution kernels to detect different features. Therefore, in order to better obtain the video feature information consistent with the video description words, the attention mechanism of the channel is proposed. Through channel attention, the model can pay more attention to the required feature graph, so that the description ability of the model is enhanced.
5.4 Attention Fusion
Given the feature characteristic obtained by fully connected layer fusion be {cᵢ}, I=1,2,3,…n, the weighted feature cᵢ’is obtained through the soft attention module, as shown in Equation. In Equation (2), βᵢᵗ represents the weight of the feature extracted from the iᵗʰ frame at time t.
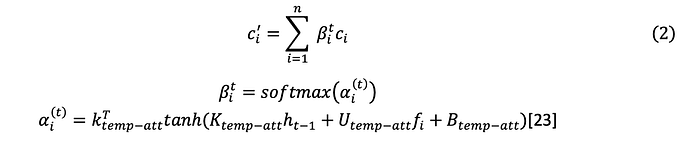
6 Caption Generation Network
6.1 Encoder
The input of the encoder is the video feature vector. The initialized hidden state is 0. The output is the LSTM output at each time and the hidden state. The dimension of LSTM output is 1×α×T. The hidden state only retains the last moment with the dimension 1×1×hidden.
6.2 Decoder
The hidden state of the decoder is initialized to the last hidden state of the output in the encoder. The input is the word token of the current word and the output is the word token of the next word. For the first word, the < BOS > state should be input. Therefore, the loss function that constrains the accuracy of caption generation is shown in Equation (3).
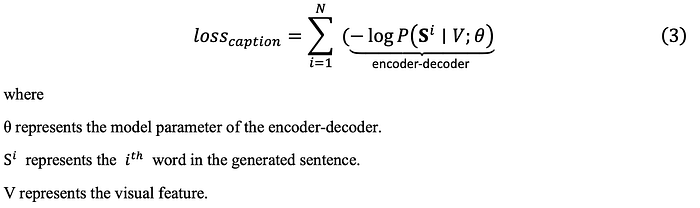
As a matter of fact, the process of caption loss training is the process of maximum likelihood estimation in Equation. The performance of the loss function in the training process is tracked.
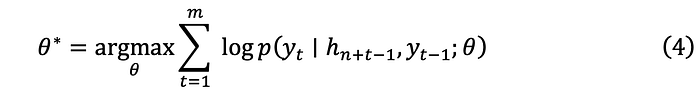
6.3 Reconstructor
The hidden state of the reconstructor is initialized to 0, and then concatenated to 1×L×(2×hidden) dimension by the decoder, and then processed to 1×1×(2×hidden) vector by soft attention to output the reconstructed video features. The loss function of reconductor is shown in Equation (5).

6.4 Overall Loss Function
The loss of the network consists of two parts: the generation part and the reconstruction part.
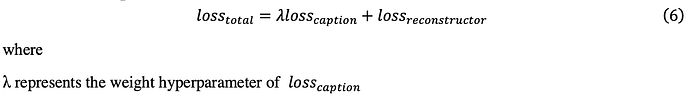
7 Ablation Experiments
Our model uses a multi-modal feature extraction module, reconstruction-based capture generation module and beam search based generation method. In order to illustrate the role of these modules, an extraction study is implemented on MST-VTT and MSVD dataset. The experimental indexes include BLEU, MENTOR, ROUGE-L, CIDER and training hours.
7.1 Multimodal Feature Extraction Module
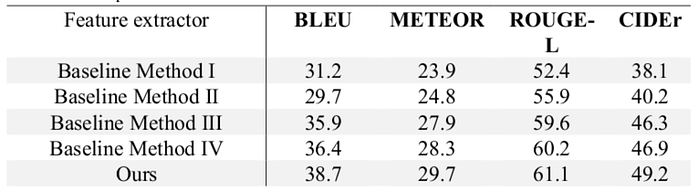
Table 1shows the experimental results of the multimodal feature extraction module. Baseline method I is used to extract features from 2D-CNN. Baseline method II is used to extract features from 2D-CNN and use temporal attention for feature fusion. Baseline method III is used to extract features from 2D-CNN + 3D-CNN, and baseline method IV is used to extract features from 2D-CNN + 3D-CNN + optical flow.
It can be seen from the table that temporary attention can improve the indicators of MENTOR, ROUGE-L, CIDER. However, BLEU is decreased slightly. 3D-CNN features can improve the four indicators of METEOR, RING-L, CIDER, AND BLEU, considerably, while flow features could only weakly improve the four indicators of METEOR, RING-L, CIDER, and BLEU. This is mainly due to the repetition of flow features and 3D-CNN features, Finally, our model adds the information of previous statement and category information on the basis of baseline method IV, which takes into account almost all features except voice features, so the performance is improved significantly.
7.2 Generation Module of Caption Based on Reconstruction
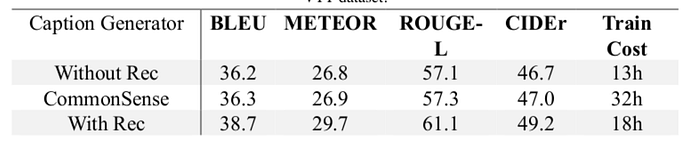
As can be seen from the above table, the reconstructor network can significantly improve the performance while it also brings more training time. At the same time, I the improvement of task performance by commonsense is tested as well. The results show that the contribution of commonsense to the performance improvement of the network is relatively weak and it also costs more training time, which is not desirable.
7.3 Comparison with the State of Art Result

In Table 3, our method is superior to other methods in METOR, ROUGE-L and CIDER, and slightly inferior to RecNet in Bleu. In addition, after feature extraction, our method only needs 10ms in the generation part of the caption, and the test environment is 8-core CPU, i7 processor, 16GB memory and python 3.7. Therefore, the performance and efficiency of this method are satisfactory.
8 Conclusion
In this article, the authors have introduced a novel approach to use I3D and 2DCNN to extract the features from video and fuse them with spatial-temporal attention with the encoder-decoder structure. The work in video captioning deals with generating natural language descriptions to describe the videos in MSR-VTT datasets. This study approaches the task of video captioning by breaking down the problem into two portions: (1) feature extraction and feature fusion in the encoder (2) using the predicted semantic tags in the caption generated by the language decoder model. The novel idea of reconstructor was proved to predict good quality tags and therefore achieved the better performance of the captioning model. The uniqueness of this result is the stability the models, especially the three different attention mechanism-based model bring to the video captioning task. The result gotten so far showcases that this is a promising direction of work that can yield even better results than following a plain encoder-decoder construct.
Reference
[1] Jia D ,Wei D , Socher R , et al. ImageNet: A large-scale hierarchical image database[J]. Proc of IEEE Computer Vision & Pattern Recognition, 2009:248–255.
[2] Simonyan K , Vedaldi A , Zisserman A . Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps[J]. Computer ence, 2013.
[3] Szegedy C , Wei L , Jia Y , et al. Going Deeper with Convolutions[J]. IEEE Computer Society, 2014.
[4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[5] Szegedy C , Vanhoucke V , Ioffe S , et al. Rethinking the Inception Architecture for Computer Vision[J]. IEEE, 2016:2818–2826.
[6] Tan M , Le Q V . EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[J]. 2019.
[7] Ji S , Xu W , Yang M , et al. 3D Convolutional Neural Networks for Human Action Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(1):221–231.
[8] Wang L , Xiong Y , Wang Z , et al. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[J]. Springer, Cham, 2016.
[9] Tran D , Bourdev L , Fergus R , et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]// IEEE International Conference on Computer Vision. IEEE, 2015.
[10] Carreira J , Zisserman A . Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017.
[11] Xie S , Sun C , Huang J , et al. Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification[J]. 2017.
[12] Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137–1149.
[13] Zhou X , Wang D , P Krhenbühl. Objects as Points[J]. 2019.
[14] Vasili Ramanishka, Abir Das, Dong Huk Park, Subhashini Venugopalan, Lisa Anne Hendricks, Marcus Rohrbach, and Kate Saenko. Multimodal video description. In ACM MM, pages 1092–1096, 2016.
[15] Yang C,Xu Y , Shi J , et al. Temporal Pyramid Network for Action Recognition[J]. IEEE, 2020.
[16] Zhu Y , X Li, Liu C , et al. A Comprehensive Study of Deep Video Action Recognition[J]. 2020.
[17] Video Description: A Survey of Methods, Datasets, and Evaluation Metrics[J]. ACM Computing Surveys, 2019, 52(6):1–37.
[18] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2758–2766.
[19] Han W, Chan C F,Choy C S , et al. An efficient MFCC extraction method in speech recognition[C]// IEEE. IEEE, 2006.
[20] Shi L, Du K , Zhang C , et al. Lung Sound Recognition Algorithm Based on VGGish-BiGRU[J]. IEEE Access, 2019, PP(99):1–1.
[21] Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.
[22] Trecvid Q A , Related S . Visualizing and Understanding Convolutional Networks [104].
[23] Yan C , Tu Y , X Wang, et al. Corrections to “STAT: Spatial-Temporal Attention Mechanism for Video Captioning”[J]. IEEE Transactions on Multimedia, 2020, 22(3):830–830.
